

マルチテナントサービスの集計バッチは、顧客の契約数の増加と共に、日々の集計対象となるデータ量が増大し、夜間の処理時間が長くなりがちです。
xross dataでは、2014年のサービス開始当初から、基本的に機械学習を利用する集計バッチはPythonで、他の集計バッチはWebアプリのクラスライブラリを流用するためにPHPで開発し、サービス機能の拡張を行ってきました。
そのような状況において、2019年9月9日にポール・エメリク氏がRustで開発したデバイスドライバの性能評価をGitHubで発表し、同氏はさまざまな言語で同じ機能を備えたデバイスドライバを開発し性能比較をしています。
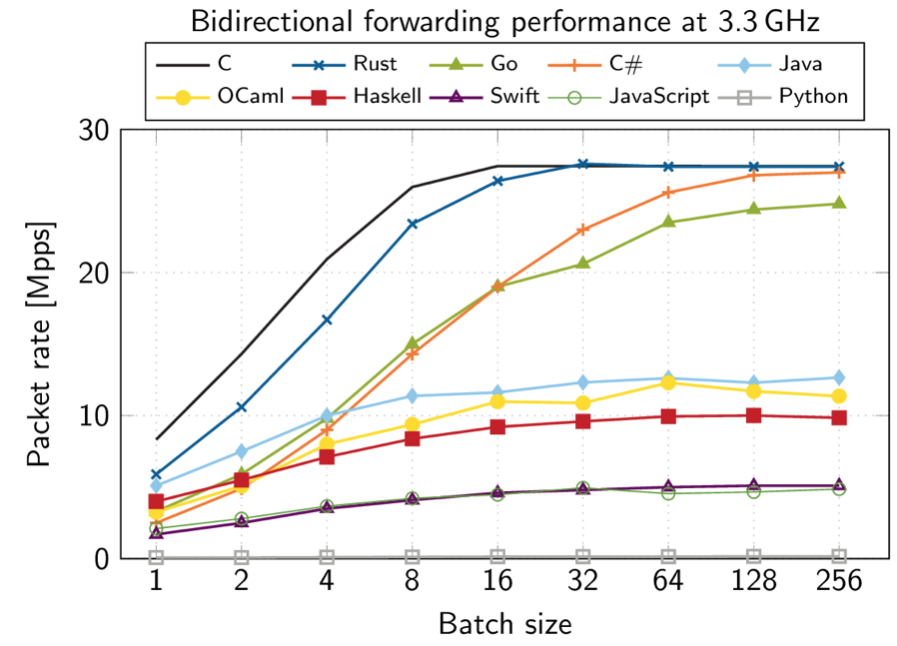
デバイスドライバと集計バッチという差異はあるものの、この性能評価結果が契機となって、他の言語への移行を検討することになりました。
そして、性能評価の結果と言語自体の将来性を考慮し、RustかGo言語のいずれかへの移行が望ましいと判断し、各言語の調査を開始しました。
xross dataでは、集計バッチの分散処理でApache Hadoopを活用しており、Hive / MapReduce / SparkとImpalaのクエリを実行できなくてはならず、当時、これらのクライアントライブラリとしてGitHubで公開されていたのがGo言語のみでした。
また、Go言語は並行処理を簡単に書くための道具が揃っている点も決め手となって、Go言語への移行を決定しました。
とはいえ、hiveserver2とimpalaのバージョンに依って利用可能なThriftのバージョンが異なるため、単にクライアントライブラリをインポートするだけでは動作せず、結局、それぞれ独自に改造する必要がありました。
このように、Go言語についてほとんど知識がないまま、Go言語への移植を行いました。
その際、幾つか嵌まった点がありましたので、ご紹介したいと思います。
引数の参照渡しと値渡し
当社が知る一般的な高級言語では、関数への値渡しは変数がコピーされ、関数に渡した値を変更したい場合は参照渡しで実装するのが通例だと思いますが、Go言語では値渡しで引数を指定した場合でも、変数の型によっては参照渡しになる型が存在します。
例えば、連想配列であるMapは参照渡しとなるため、引き渡し先で書き換えが必要な場合でも、ポインタを利用する必要がありません。
すなわち、処理の高速化を意識して、巨大なMap変数を引数としてポインタ渡しで実装したとしても、処理はほとんど高速化されないはずです。
このように、変数の型に応じて引数の渡し方が異なることを理解しておいた方が良いと思います。
パッケージ名の制約
集計バッチを開発する際に、ディレクトリ構成に悩みましたが、スタンダードがあるということで、そちらを参考にしたディレクトリ構成としました。
参考)https://github.com/golang-standards/project-layout
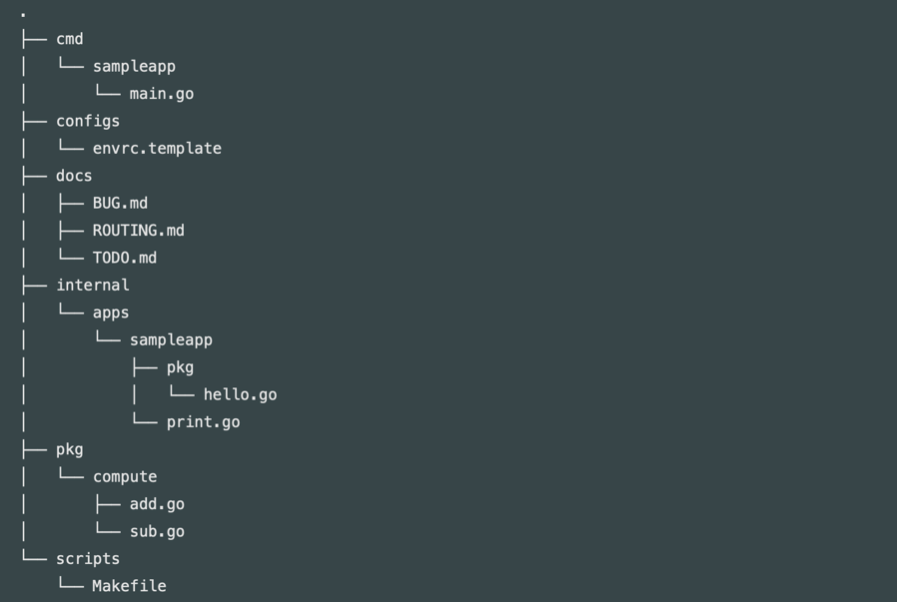
集計バッチはコマンドラインで実行するソフトウェアなので、下図のsampleappのようにcmdディレクトリ配下にコマンド単位でディレクトリを作成しました。
その場合、main.goだけでなく、同一のディレクトリ内に幾つかのソースコードファイルを配置することになりますが、それらはすべて同じパッケージ名を付けなければならないという制約があります。
もし異なるパッケージ名を付与するためには、階層的にディレクトリを作成し、そこに配置する必要があります。
例外処理がない
これはもう有名な話で、Go言語の2大ディスりポイントの1つとなっています(余談ですが、もう1つはGenericsがないこと)。
個人的には、例外処理が存在しないなどの制約があるからこそ、様々なメリットがあるわけなので、無ければ無いで、柔軟に対応すれば良いと思っています。
具体的には、errorインタフェースが用意されており、関数を自作する場合も含め、返値の1つを必ずerror型変数を用意し、呼び出し側ではその変数がnilかどうかをチェックし、nilでなければ、エラー処理をするというのがお作法となっています。
データベースのコネクションプーリング
データベースアクセスで利用する標準搭載のdatabase/sqlパッケージには、コネクションプール機能があり、1つのデータベースに対して複数のステートメントを実行した場合、異なるコネクション経由でステートメントが実行される可能性があります。
すなわち、テーブルロック開始のステートメントの後に実行した挿入ステートメントがブロックされたり、Goroutineを使って並行処理している場合には、連続する更新処理が、他に実行されたコミットステートメントにより更新クエリがブロックされ、急にエラーとなったりします。
また、デフォルト設定のままだと、確立するコネクション数に制限がないため、データベース側で設定しているコネクション数の上限値に達成してしまい、ある日、突然データベース側のコネクションプールが枯渇し、コネクションが生成できず、バッチがエラーとなったりします。
まず、前者の問題については、トランザクション機能を利用することで、同一コネクション経由でのステートメント実行が保証されます。また、Goroutine間のクエリを分離するためには、sql.DB変数をGoroutine毎に分離することで、対処できます。
一方、後者の問題については、以下の設定関数を呼び出すことで対処できます。設定する値は、環境に応じて変える必要があります。
- SetMaxOpenConns(int n) : 生成できるコネクションの最大数
- SetMaxIdleConns(int n) : プールできるアイドル状態のコネクションの最大数
- SetConnMaxLifetime(int n * time.Second) : 再利用され得る最長時間[秒]
まとめ
今回は記載しませんでしたが、変数と関数の大文字始まりと小文字始まりの違いや、日付のフォーマットが”2006-01-02 15-04-05”とするなど、Go言語は様々な制約の代償として、高速なコンパイルなどのメリットを生み出しています。
その制約を知ってしまえば、なんてことないように思いますが、知らずに実装していると、心が折れそうなほどの戻り作業が発生するケースがあったりします。
xross dataのバッチ開発も、紆余曲折がありながらも、なんとか開発が完了し、先日ようやくサービス環境の機械学習を利用するバッチ以外のすべてのバッチをGo言語製のバッチに移行できました。
その結果、処理時間を短縮できたのは言語の差というよりは、むしろGoroutineを活用した並行処理によるものでした。
Go言語はGoroutineを利用することで、非常に簡単に並行処理を記述できます。
xross dataのバッチでは、並行化できる処理はすべて並行処理として実装しました。
また、xrossdataの日次の集計バッチでは、ワークフローツールを利用して実行管理をしており、バッチ間の依存関係を考慮しながら、マルチプロセスで並列的に処理しています。
そこにGo言語製のバッチを導入することで、マルチプロセスによる並列処理に加えて、Goroutineによる並行処理も実現しています。
このように、限られたサーバ及びインフラリソースをできるだけ有効活用して、処理時間を短縮するために日々悪戦苦闘しています。
今後は機械学習を利用するPython製の集計バッチもJuliaへの移行を検討する予定です。









